


Google Cloud Platform Technology Nuggets - July 1-15, 2025 Edition

Welcome to the July 1–15, 2025 edition of Google Cloud Platform Technology Nuggets. The nuggets are also available on YouTube.
AI and Machine Learning

DORA needs no introduction. It is the largest and longest running research program of its kind, that seeks to understand the capabilities that drive software delivery and operations performance. Its interesting to see this research at the intersection of tools and performance in the age of AI. The DORA survey is now open and it would be great if you can share your team’s practices and contribute to industry-leading research. The last date is July 18, 2025. Check out the blog post for more details or jump directly to the survey.
Memory is what makes an Agent engage in a back and forth conversation and build a useful context while addressing user queries. But Agents are often limited by not just the context window size but often to judiciously use that to conserve costs while at the same time provide quality answers. Memory Bank, the newest managed service of the Vertex AI Agent Engine, has been announced to help you build highly personalized conversational agents to facilitate more natural, contextual, and continuous engagements. It is integrated with the Agent Development Kit (ADK) and Agent Engine Sessions. Check out the blog post to understand how it works, getting started and more.

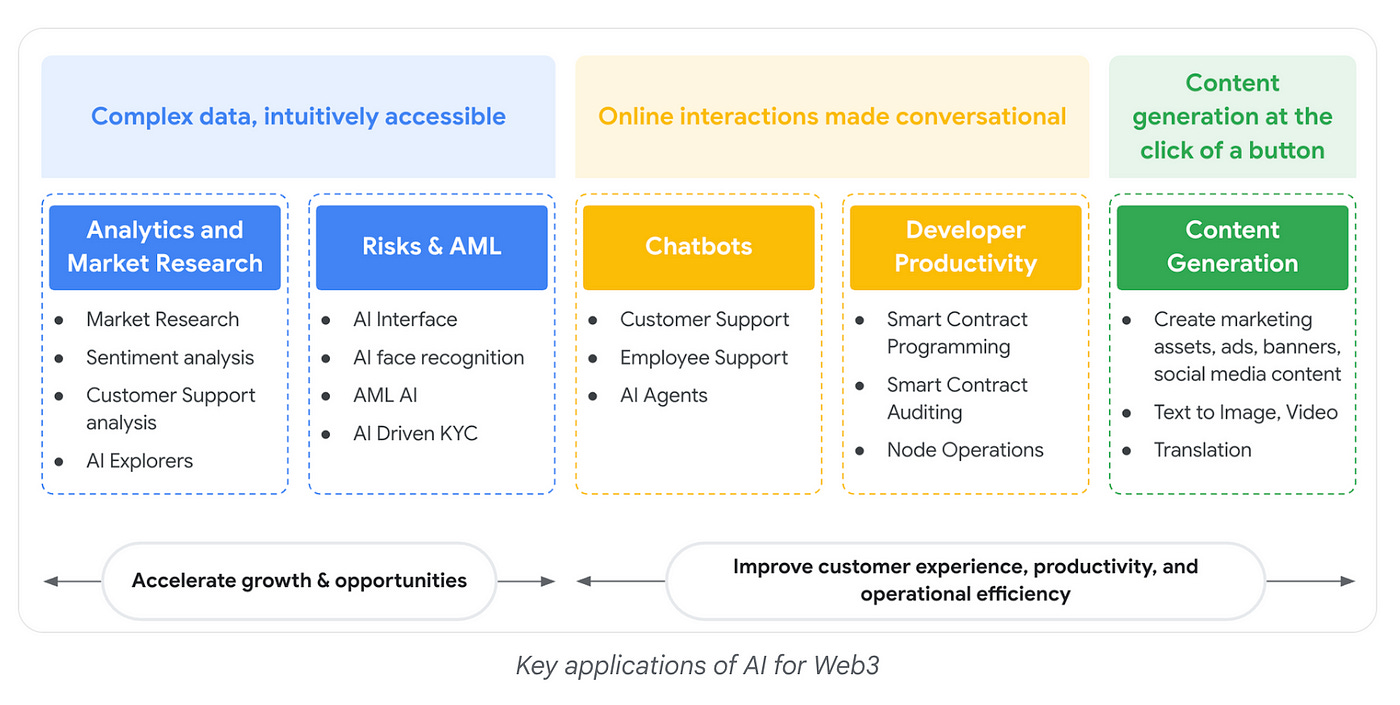
AI and Web3 form an interesting combination of technologies and specifically AI Agents for Web3, that could function within the Web3 ecosystem and address use cases like managing DeFi portfolios and executing transactions. This blog post is a call to apply AI in a calculated fashion to Web3. It highlights the intersection of the two and its applicable use cases. It provides information on key Google Cloud services like Vertex AI Builder and Agent Development Kit (ADK) to build agents and Vertex AI Agent Engine to deploy the agents.
Google has been named a Leader in the Gartner® Magic Quadrant™ for Search and Product Discovery. To download the full 2025 Gartner Magic Quadrant for Search and Product Discovery report, click here.

Containers and Kubernetes
If you are looking to effectively manage backups across project boundaries for your GKE deployments, then there is a new service in preview called Backup for GKE. It supports cross-project backup and restore, allowing you to back up workloads from a GKE cluster in one Google Cloud project, securely store the backups in a second, and restore them to a cluster in a third. Check out the blog post to get started.

Identity and Security
The 2nd CISO bulletin for June 2025 is out. It highlights the evolving landscape of cyber threats, specifically targeting European healthcare organisations. Key services mentioned, specifically keeping the geography in mind include Confidential Computing and Sovereign Cloud, to ensure the secure and compliant handling of sensitive patient data in the EU.
Data Analytics
If you found complex nested SQL difficult to read/write, you are not alone. A pipe-structured data flow makes SQL more easier to read and write than ever before and to address this, Google introduced pipe syntax, an extension to GoogleSQL that reimagines how queries are written and processed. To highlight a few key points from the blog, “ it provides a linear, top-down approach to SQL queries, using the pipe operator (|>) to chain operations like filtering, aggregating, and joining in a logical sequence. Additionally, pipe syntax allows operations to be applied in any order, reducing the need for cumbersome subqueries or Common Table Expressions (CTEs).” Check out this blog post that highlights three different use cases from customers about how they are using pipe syntax to simplify data transformations and log data analysis and most importantly, whats coming next in this area.

Its no secret that you can do wonders with the basic aggregate functions like SUM, AVG, and COUNT while doing your data analysis. But BigQuery wants to take it to the next level with advanced aggregate functions, which include:
Group by extension (grouping sets/cube, group by struct, array, group by all)
User-defined aggregate functions (Javascript/SQL UDAFs)
Approximate aggregate functions (KLL quantiles, Apache DataSketches)
If that makes your curious, check out the blog post for more details including SQL scripts for these new aggregate features.

TimesFM, a state-of-the-art pre-trained model from Google Research is now available in BigQuery. This model is pre-trained on a large time-series corpus of 400 billion real-world time-points, can perform “zero-shot” forecasting. This means that it can make accurate predictions on unseen datasets without any training. Since this model inference runs directly on BigQuery infrastructure, there are no models to train, endpoints to manage, connections to set up, or quotas to adjust. This is available to you via the AI.FORECAST function. Check out the blog post for more details.

Databases
AlloyDB performance snapshot report! In simple words, it is a new feature of AlloyDB for PostgreSQL, that helps you understand database performance. It is a collection of PostgreSQL functions and views that captures snapshots of your AlloyDB system statistics. These snapshots provide detailed diff reports of performance metrics between different points in time, offering a comprehensive view of your database’s activity during the period. Check out the blog post for its features and how it works.

Application Development
Developers building Agentic systems have moved from basic single purpose Agents to Agents that use a suite of tools and do a complex set of tasks. It is often recommended that instead of putting all that logic into a single Agent and making it more complex, one should separate the logic into multiple agents and construct a Multi-Agent system, often with a co-ordinator Agent that orchestrates the work between the different agents. If you are looking for guidance on how to construct a multi-agent system, check out this blog post that provides step by step guidance vis-a-vis the Agent Development Kit (ADK) to first construct the individual agents, then equip the agents with their respective tools, create a co-ordinator agent, consider doing tasks in parallel, having a feedback loop and more.

The Agent to Agent Framework (A2A) is the industry leading and open source protocol to facilitate communication and collaboration between AI agents from different frameworks and vendors. If you have been using the Agent Development Kit (ADK) to develop a standalone Agent that uses MCP Tools, the next progression would be to enable this Agent to participate in the A2A ecosystem. How do you make your Agents ready for A2A interactions? This blog post gives you a step by step approach to making this happen starting from defining your agent to the A2A requirements like Agent Card, Agent Skill, Invocation, Discoverability and more.

One of the key things while working with LLMs is to ground them to existing data and one of the sources is the web. Jina Reader is a popular service that provides reliable, LLM-friendly web content. Behind the scenes of Jina Reader, is ReaderLM-v2, is a purpose-built 1.5-billion-parameter language model that intelligently extracts content, trained on millions of documents to understand web structure beyond simple rules. Cloud Run played a crucial role in making the following happen and I quote from the post:
The web grounding app (the browser automation system that scrapes and cleans web content) is hosted on Cloud Run (CPU). It runs full Chrome browser instances.
ReaderLM-v2 is a purpose-built 1.5-billion-parameter language model for HTML-to-markdown conversion that runs on Cloud Run with serverless GPUs.
Check out this customer story that highlights how Jina Reader was able to process 100 billion tokens daily efficiently and securely.

Developers & Practitioners
Google Cloud is collaborating with Docker to simplify your deployment workflows, enabling you to bring your sophisticated AI applications from local development to Cloud Run with ease. But what does that mean? They have taken the open-source Compose Specification, which is primarily used to construct applications in the local environment and introduced a new command gcloud run compose up. This will deploy the existing compose.yaml file to Cloud Run, including building containers from source and leveraging Cloud Run’s volume mounts for data persistence. The service is currently available in private preview. Check out the blog post for more details.

Infrastructure
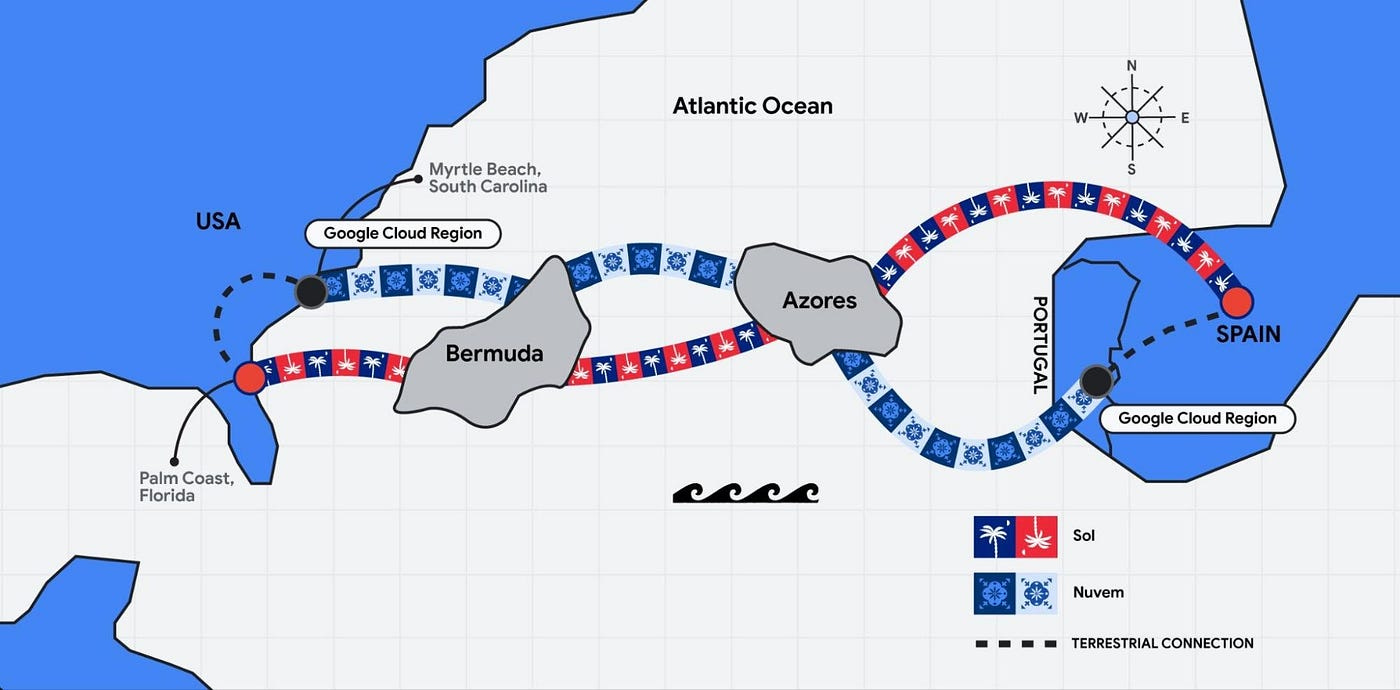
Google has announced a new Sol subsea cable, a transatlantic fibre-optic system connecting the U.S. (Florida), Bermuda, the Azores, and Spain. Once operational, it would boost the capacity and reliability the network of 42 Google Cloud regions around the world, helping meet growing customer demand for Google Cloud and AI services across the U.S., Europe, and beyond. Check out the blog post.
Google Cloud’s Z3 Storage Optimized VM family has expanded with nine new virtual machines offering diverse local SSD capacities and a Z3 bare metal instance. As mentioned in the blog post, “Z3 VMs are designed to run I/O-intensive workloads that require large local storage capacity and high storage performance, including SQL, NoSQL, and vector databases, data analytics, semantic data search and retrieval, and distributed file systems. The Z3 bare metal instance provides direct access to the physical server CPUs and is ideal for workloads that require low-level system access like private and hybrid cloud platforms, custom hypervisors, container platforms, or applications with specialized performance or licensing needs.”
Business Intelligence
Conversational Analytics API helps you build an artificial intelligence (AI)-powered chat interface, or data agent, that answers questions about structured data in BigQuery, Looker, and Looker Studio using natural language. This API is currently available in preview, integrates multiple AI-powered tools to process user requests, including Natural Language to Query (NL2Query) and a Python code interpreter for generating responses. Check out the blog post that gives you a peek into the engine powering this API, how it builds the context based on information provided by the type of the data source and more. This API could eventually help you build your own custom agents that could tap into your BigQuery and Looker data.

Storage and Data Transfer
One would assume that moving storage buckets from one location to another would be a straightforward thing but its not. In a first of kind feature among cloud hyperscalers, Google Cloud has introduced Cloud Storage bucket relocation, that makes this task easy. Your bucket’s name, storage class and all the object metadata within it, remain identical throughout the relocation, so there are no path changes. Check out the blog post that explains how this works under the hood and steps to get started.

Write for Google Cloud Medium publication
If you would like to share your Google Cloud expertise with your fellow practitioners, consider becoming an author for Google Cloud Medium publication. Reach out to me via comments and/or fill out this form and I’ll be happy to add you as a writer.
Stay in Touch
Have questions, comments, or other feedback on this newsletter? Please send Feedback.
If any of your peers are interested in receiving this newsletter, send them the Subscribe link.