
Google Cloud Platform Technology Nuggets : March 16-31, 2026

Welcome to the March 16–31, 2026 edition of Google Cloud Platform Technology Nuggets. The nuggets are also available on YouTube.
Google Cloud Next 2026
The biggest event of the year, Google Cloud Next 2026, is just a few weeks away. Keynotes will be live streamed. Do register for the same, even if you cannot make it in person.

AI and Machine Learning
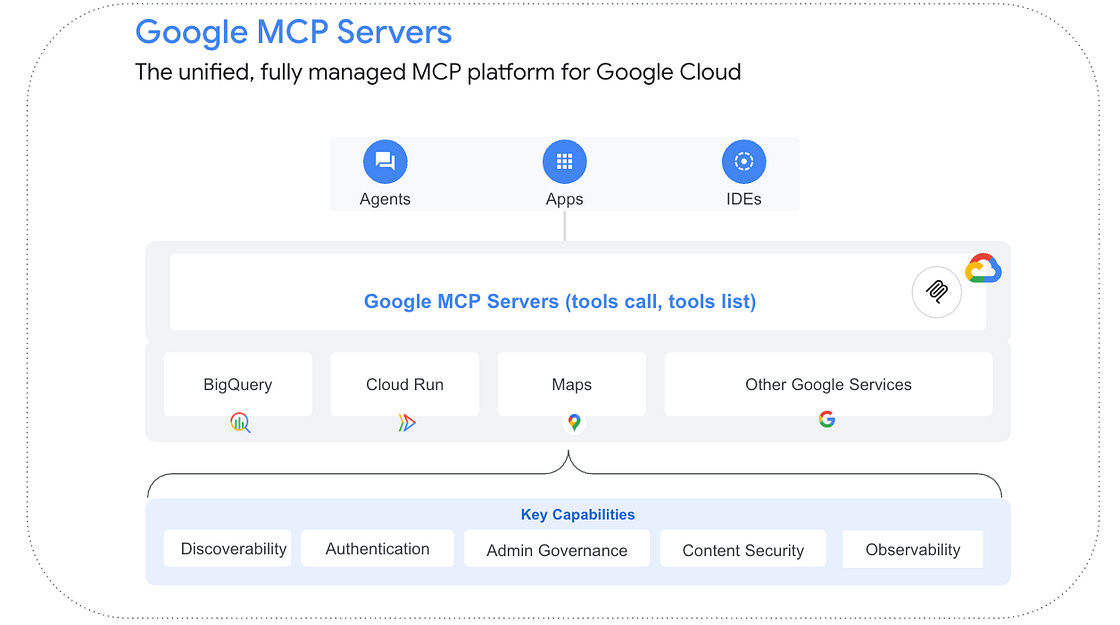
Google-managed Model Context Protocol (MCP) servers provide a production-ready infrastructure for AI agents to interact with services like Google Maps, BigQuery, and Google Cloud Databases without the need for manual backend provisioning. These servers offer native integration with the Google Cloud security stack, enabling developers to enforce granular tool-calling permissions through IAM deny policies and sanitize inputs using Model Armor to prevent prompt injections. Check out the blog post that provides this introduction along with the detailed use of the Application Development Kit (ADK) to connect agents to both remote managed endpoints for real-time data.
Data Analytics
If you’d like to bookmark a single page that keeps a track of all things announced in the Google Cloud Data world, bookmark “Whats New in Google Data Cloud”. Latest announcements in this space include the the introduction of an enhanced Gemini assistant in BigQuery Studio that acts as a context-aware analytics partner and Cloud SQL autoscaling read pools to dynamically manage read capacity via a single endpoint.
Databases
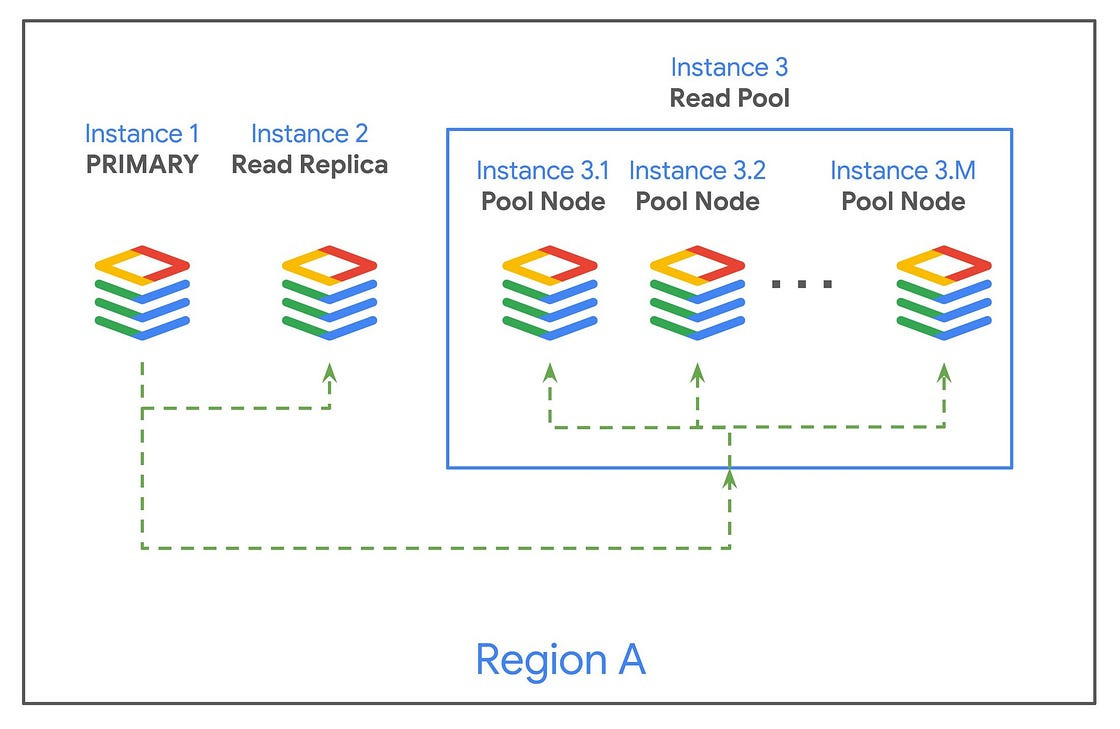
Cloud SQL has introduced autoscaling for read pools in the Enterprise Plus edition for MySQL and PostgreSQL, providing a managed solution to handle variable read-heavy workloads. A read pool, groups 1 to 20 identical read replicas behind a single, stable read endpoint that uses round-robin load balancing to distribute traffic. The autoscaling feature dynamically adjusts the number of nodes based on real-time metrics such as CPU utilization or the number of database connections. This architecture allows developers to scale read capacity without changing application code or manually managing individual replicas. For more details, check out the blog post.
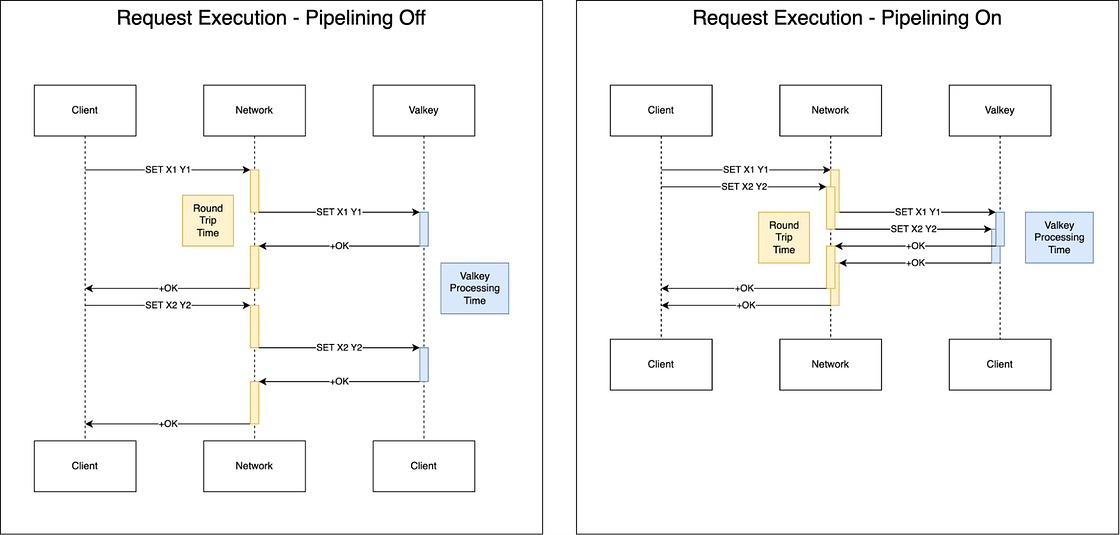
Google Cloud has announced the General Availability (GA) of Valkey 9.0 on Memorystore, introducing architectural changes designed to increase throughput and reduce latency. Key technical updates include pipeline memory prefetching, which improves memory access efficiency to boost throughput by up to 40%, and zero-copy responses that reduce internal memory overhead for large requests. Additionally, the update supports clustered database configurations for up to 100 numeric databases and provides enhanced client filtering for debugging. Check out the blog post.
Security and Identity
The RSA Conference (RSAC) ’26 is a major cybersecurity event where industry leaders gather to discuss evolving threats and defense strategies. The 2026 theme centered heavily on the shift toward agentic AI, focusing on how autonomous AI agents can be used both by attackers to accelerate intrusions and by defenders to secure environments at machine speed. Google Cloud’s primary role at RSAC ’26 was highlighting “agentic defense” using autonomous AI agents to counter high-velocity cyberattacks.
The 2nd Cloud CISO perspectives for March 2026 is out. It covers insights from RSAC ’26, focusing on how organizations are moving through a three-stage AI journey: automating tasks, redesigning workflows, and rethinking entire functions like the Security Operations Center (SOC).
Developers & Practitioners
In the first of a four-part series, that highlights how to build a multi-agent system, learn about how to build Dev Signal, a multi-agent system designed to automate technical content creation by identifying trending questions on Reddit and grounding them in official documentation.
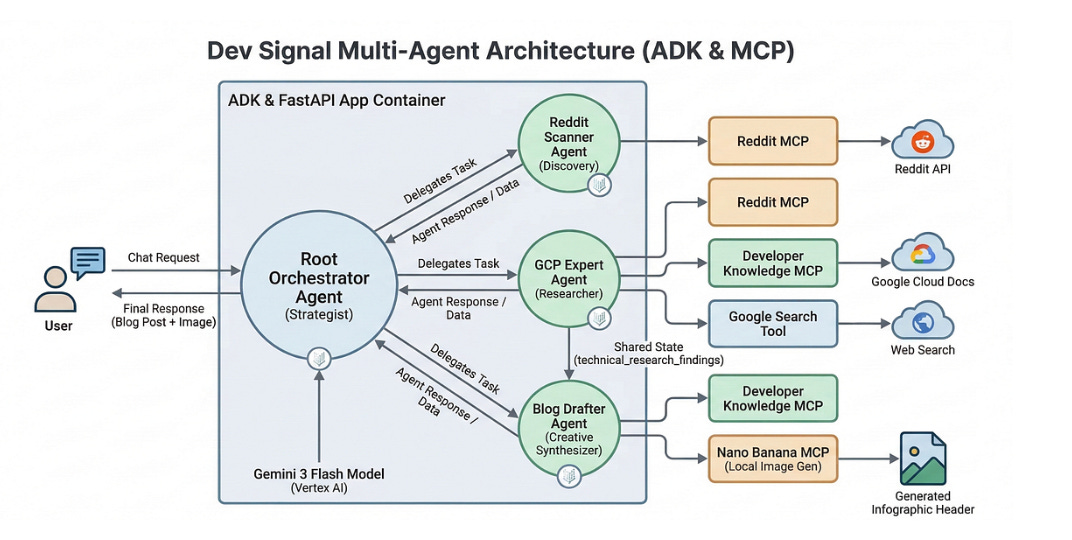
The core of the project focuses on using the Model Context Protocol (MCP) to standardize how AI agents interact with external tools and data:
Discovery: A Reddit MCP server allows the agent to find high-engagement technical questions.
Grounding: The Developer Knowledge MCP server enables the agent to perform semantic searches across official Google Cloud documentation for accuracy.
Multimodal Generation: A custom “Nano Banana” MCP server uses Gemini 3 Pro Image to generate professional infographic headers for the blog posts.
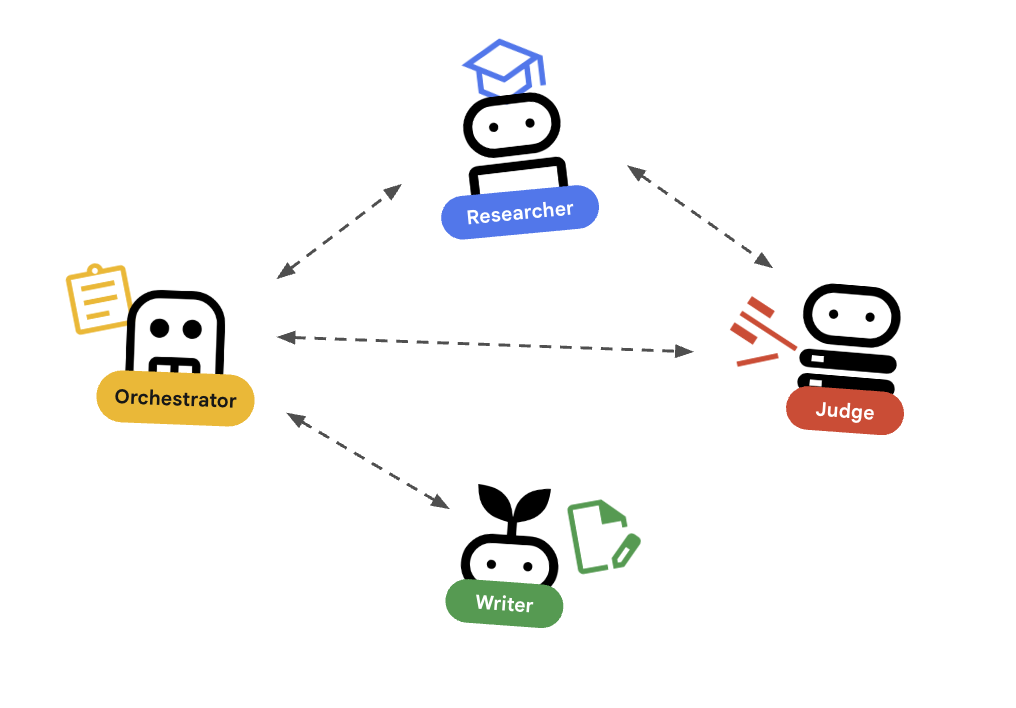
Looking for guidance on how to build out distributed AI Agents, that work independently but in close orchestration as needed? Check out this article tha outlines the orchestrator pattern for building distributed AI agents as independent microservices rather than monolithic scripts. By using the Agent Development Kit (ADK), developers can create specialized agents, such as a researcher for data gathering and a judge for quality assurance using Pydantic for structured output. These agents communicate via the Agent-to-Agent (A2A) protocol over HTTP, allowing them to be deployed and scaled independently on Cloud Run. An orchestrator agent manages the workflow, retries, and state, providing a single integration point for frontend applications.
LLM inference involves a tradeoff between latency and throughput. You absolutely want to maximize your usage of hardware but still keep your costs in check. To achieve this, as the blog post indicates, developers can implement key core techniques, a few of which include:
Semantic routing to direct simpler tasks to smaller models
Disaggregation of the compute-heavy prefill phase from the memory-bound decode phase, and quantization to reduce model weight precision for faster memory reads
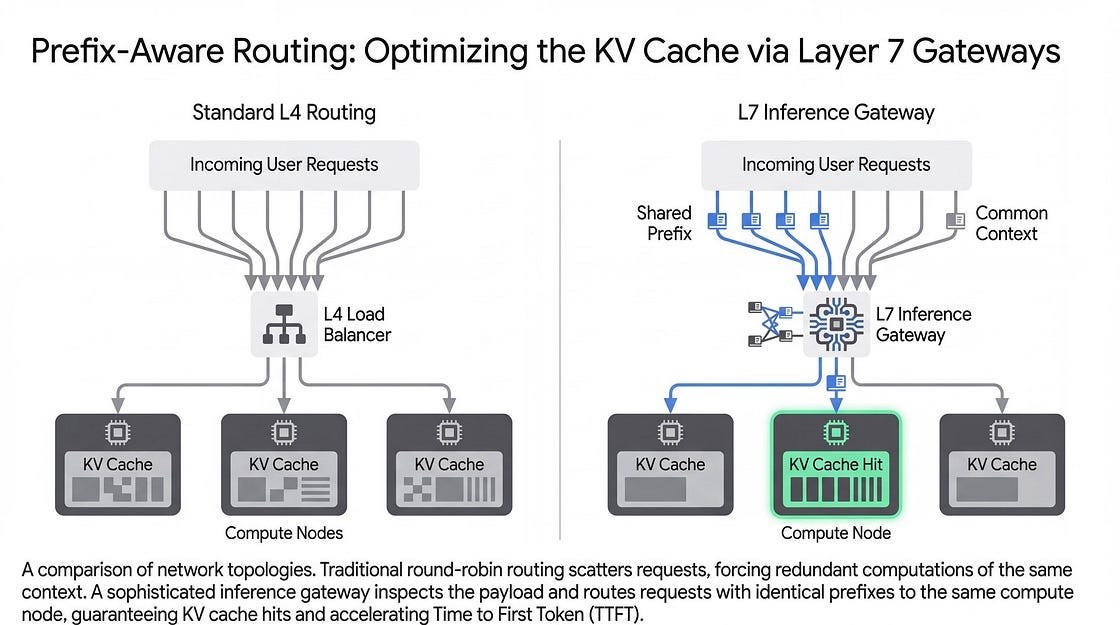
Prefix caching combined with context-aware L7 routing prevents redundant computations by reusing stored KV caches
By adopting these methods, such as through the GKE Inference Gateway on Google Cloud Platform, practitioners can optimize hardware utilization and reduce costs.
Research conducted with UC Berkeley students and experienced developers indicates that AI is being integrated into technical workflows as a strategic learning partner rather than a shortcut for task completion. Key findings highlight that students use AI as a “24/7 tutor” to explain complex concepts, debug code, and bridge knowledge gaps, particularly for those with learning disabilities. To prevent overdependence and “cognitive debt,” developers employ active resistance strategies such as hand-coding fundamental logic and limiting AI use to mechanical tasks like boilerplate code. Check out more of these interesting details in the blog post.
Containers and Kubernetes
There are several Container, Kubernetes and GKE updates in this edition of the newsletter.
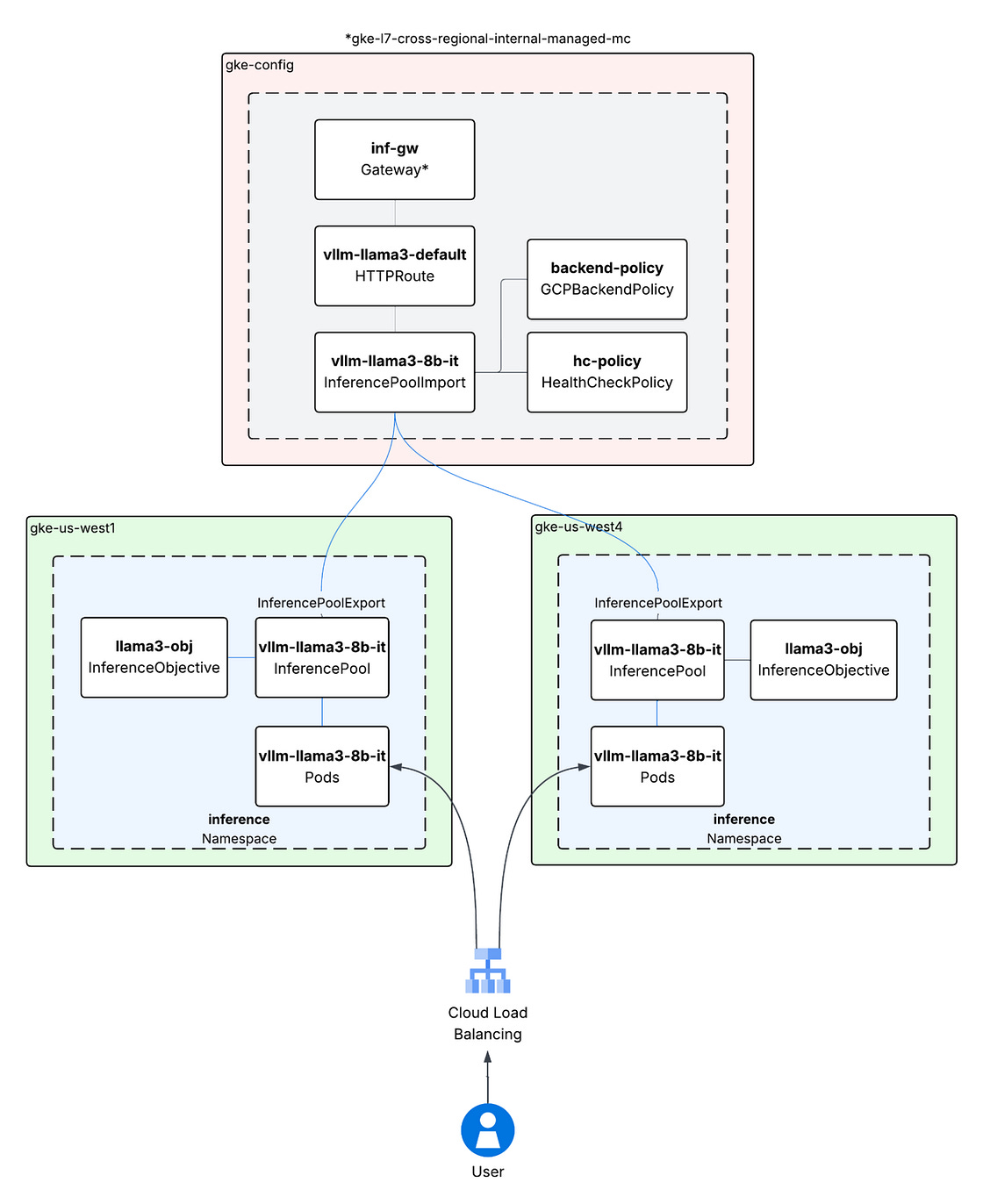
First up, what is a multi-cluster GKE Inference Gateway? It is a tool designed to manage and scale AI inference workloads across multiple Google Kubernetes Engine clusters and regions. Built as an extension of the GKE Gateway API, it uses a centralized “config cluster” to route traffic to “target clusters” where the models are hosted. The system introduces two primary resources: InferencePool, which groups model-server backends sharing specific hardware like GPUs or TPUs, and InferenceObjective, which defines model names and serving priorities. It supports model-aware load balancing through the GCPBackendPolicy, allowing traffic distribution based on real-time signals such as KV cache utilization or in-flight request limits. This architecture aims to address hardware limits within single regions, reduce latency by routing to closer clusters, and provide automatic re-routing during regional outages. For more details, check out the blog post.
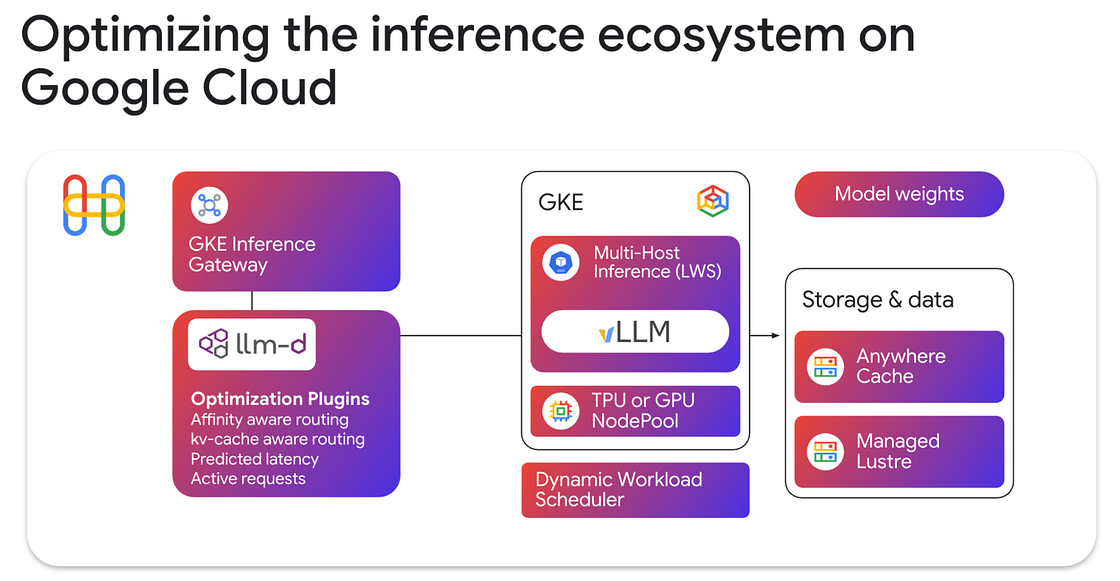
Google is updating Google Kubernetes Engine (GKE) to allow Autopilot compute classes within Standard clusters, enabling per-workload serverless scaling without requiring new clusters. The platform is now certified under the CNCF Kubernetes AI Conformance program, supporting standards like llm-d for distributed inference and Dynamic Resource Allocation (DRA) for hardware-agnostic management of TPUs and GPUs. To support AI agents, GKE is integrating the Model Context Protocol (MCP) for infrastructure management, gVisor-backed sandboxing for code execution, and Pod Snapshots to reduce startup latency. Additionally, Ray on GKE now supports TPUs and includes a new History Server for post-job debugging and observability. For more details, check out the blog post.
llm-d has officially become a CNCF Sandbox project, marking a major milestone in open-source AI infrastructure. Co-founded by Google Cloud, Red Hat, IBM Research, CoreWeave, and NVIDIA, the project aims to standardize distributed AI inference across any model, accelerator, or cloud. By integrating with Kubernetes through tools like the Endpoint Picker (EPP) and LeaderWorkerSet (LWS), llm-d enables intelligent, model-aware routing that significantly reduces latency and doubles prefix cache hit rates. Check out the blog post.
Dynamic Resource Allocation (DRA) is a new Kubernetes standard that replaces the static, integer-based Device Plugin framework with a flexible, request-based model for managing hardware like GPUs and TPUs. By utilizing ResourceSlices to describe hardware capabilities and ResourceClaims to define specific workload requirements (such as VRAM or interconnectivity), DRA allows the scheduler to automate node selection and optimize resource utilization. This feature is now available in Kubernetes 1.34 and generally available in GKE, eliminates manual node pinning and enables more granular control over expensive AI infrastructure. Check out the post.
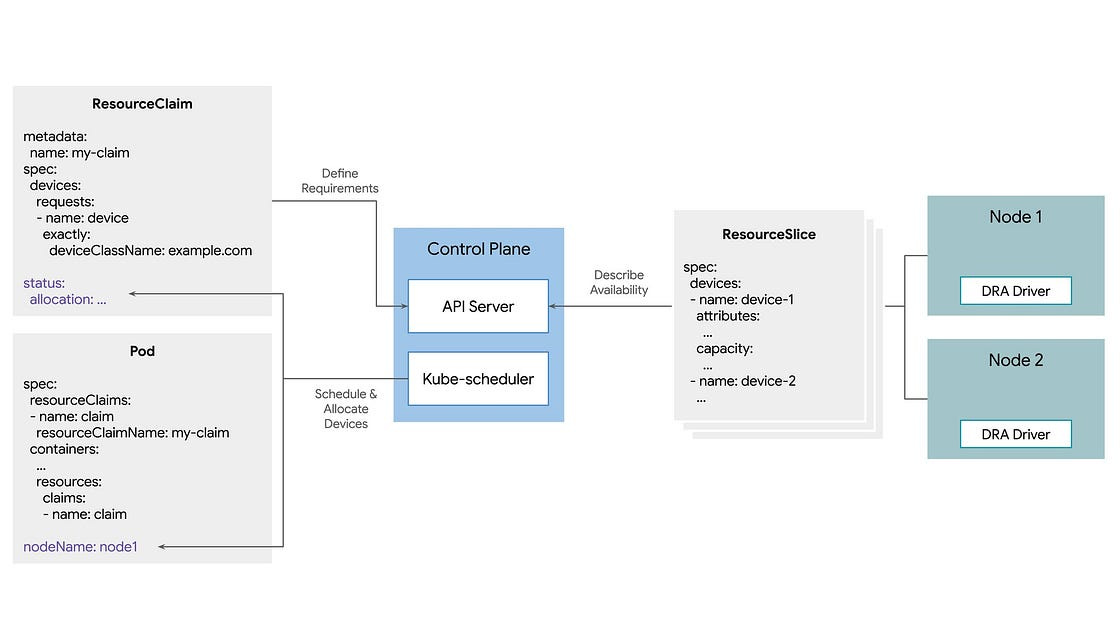
Infrastructure
Google’s seventh-generation Ironwood TPU architecture is designed to scale up to 9,216 chips using Inter-Chip Interconnect (ICI) and Optical Circuit Switch (OCS) technologies. It introduces native FP8 support in its Matrix Multiply Units to increase throughput and utilizes SparseCores to handle collective communication operations, which allows TensorCores to focus on primary model computations. For more details, check out the blog post.
Customers
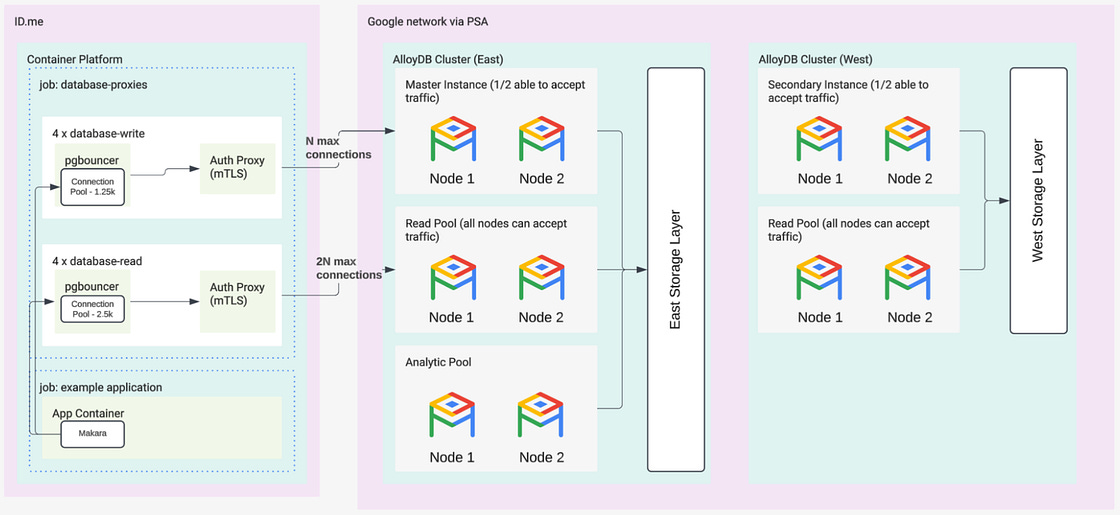
ID.me migrated 50 terabytes of data to Google Cloud to support a member base that grew to 160 million users and peak demands of 40,000 users per minute. The technical architecture uses a two-tier database system where Cloud SQL handles standard services while AlloyDB manages heavy workloads and high-concurrency tasks, such as the 120,000 transactions per second processed for the IRS. By utilizing AlloyDB read pools, the team created isolated data environments for fraud analysts to perform real-time detection and remediation using AlloyDB AI. For more details, check out the blog post.
Manhattan Associates modernized its Manhattan Active SaaS platform by migrating legacy Oracle and DB2 infrastructure to Google Cloud SQL and BigQuery. The new architecture uses Google Kubernetes Engine (GKE) to run containerized microservices, with Pub/Sub managing data streams and Cloud Logging and Cloud Monitoring providing observability. This configuration supports over a billion API calls daily with response times under 150 milliseconds and handles hundreds of thousands of daily scaling events. For more details, check out the blog post.
Write for Google Cloud Medium publication
If you would like to share your Google Cloud expertise with your fellow practitioners, consider becoming an author for Google Cloud Medium publication. Reach out to me via comments and/or fill out this form and I’ll be happy to add you as a writer.
Stay in Touch
Have questions, comments, or other feedback on this newsletter? Please send Feedback.
If any of your peers are interested in receiving this newsletter, send them the Subscribe link.