
Google Cloud Platform Technology Nuggets - March 1-15, 2026

Welcome to the March 1–15, 2026 edition of Google Cloud Platform Technology Nuggets. The nuggets are also available on YouTube.
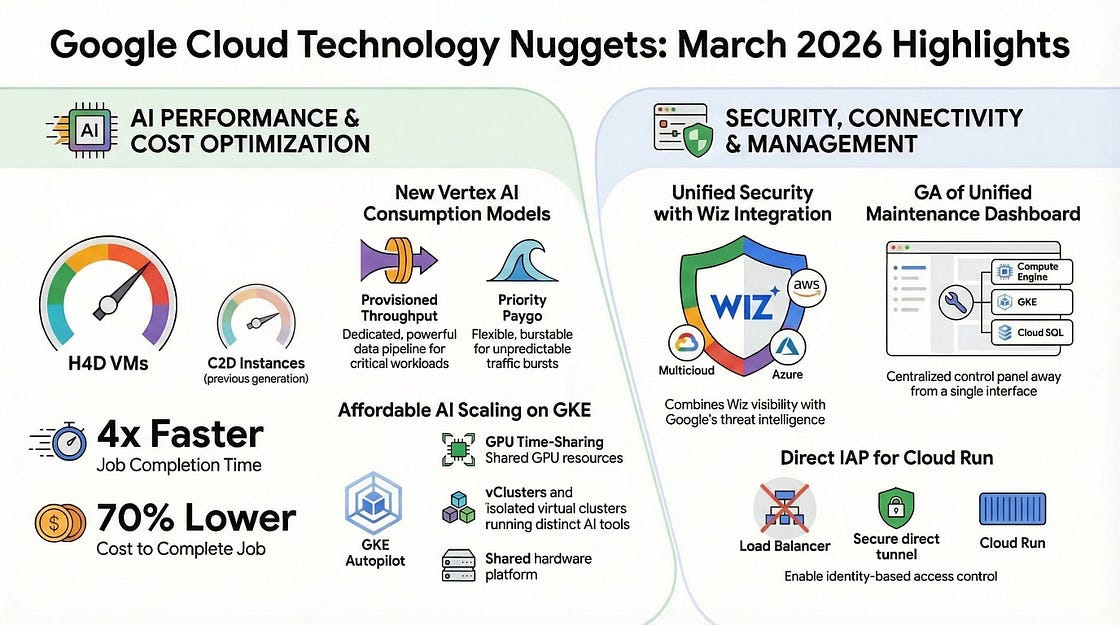
An infographic summarizing the key announcements in this blog post (courtesy NotebookLM):
AI and Machine Learning
Google has published the Ultimate Nano Banana prompting guide, that covers:
Model overview
Full breakdown of tech specs
Best practices for effective prompting
Prompting frameworks
How Nano Banana works with other creative models, Veo and Lyria.

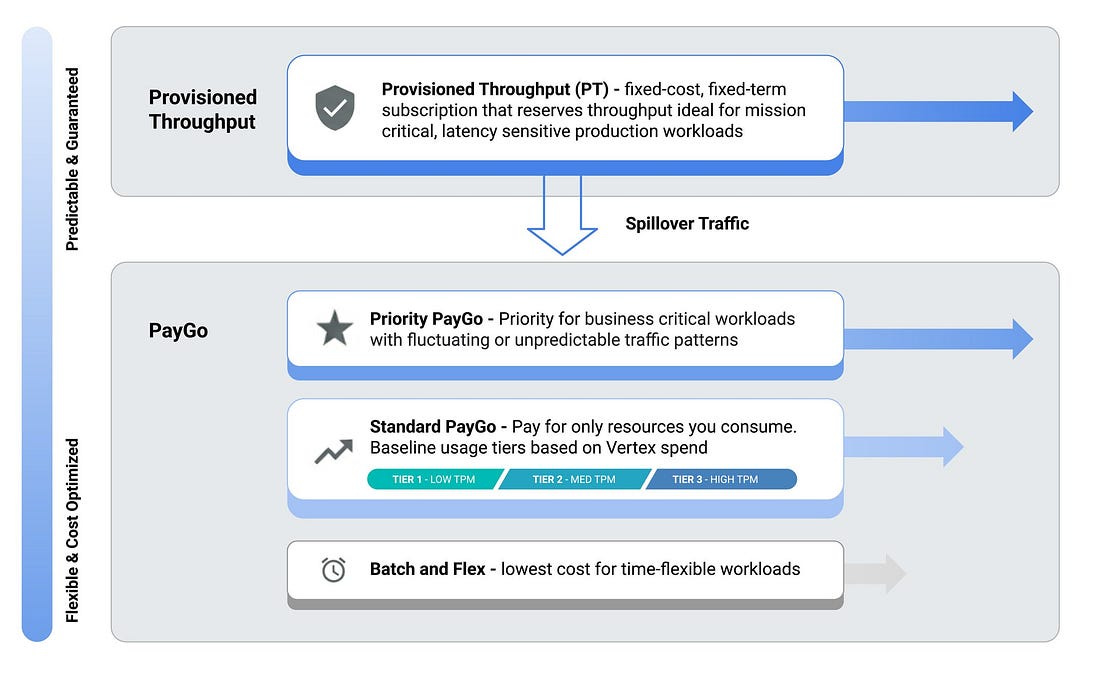
Consistently hitting 429 (Resource Exhausted) errors in Vertex AI? This article highlights aligning consumption models with specific application traffic patterns. When it comes to consumption models, developers can utilize Standard Pay-as-you-go for baseline needs, Priority Paygo for critical bursts, or Provisioned Throughput for guaranteed, isolated capacity. Key technical best practices include implementing exponential backoff, using global model routing to distribute requests across regions, and leveraging context caching to reduce redundant token processing. Additionally, the text highlights prompt optimization techniques , such as using Gemini 2.5 Flash-Lite for summarization and more.
Management Tools
Google Cloud has announced the General Availability of Unified Maintenance, a centralized dashboard designed to manage planned maintenance across multiple services. This tool consolidates maintenance schedules for Compute Engine, Google Kubernetes Engine (GKE), Cloud SQL, Memorystore, AloyDB, and Looker. It integrates with Cloud Logging to provide standardized alerts, enabling developers to automate notifications or connect events to existing ticketing systems. Check out the blog post.
Security and Identity
Google Cloud has completed the acquisition of Wiz to integrate its cloud-native security capabilities into a unified platform. The integration combines Wiz’s continuous visibility across code, cloud, and runtime with Google’s threat intelligence and operations tools. The combined solution supports multicloud environments including AWS, Azure, and Oracle, while utilizing Gemini AI models to automate threat hunting and remediation workflows. Check out the details.

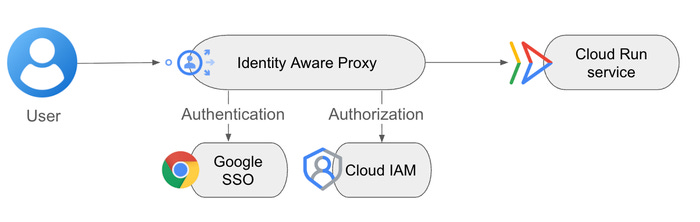
Direct Identity-Aware Proxy (IAP) integration for Cloud Run is now available, allowing users to enable identity-based access control without manual configuration of application load balancers. This integration supports Workforce Identity Federation and allows for the configuration of CORS by permitting unauthenticated HTTP OPTIONS requests. Check out the blog post for more details.
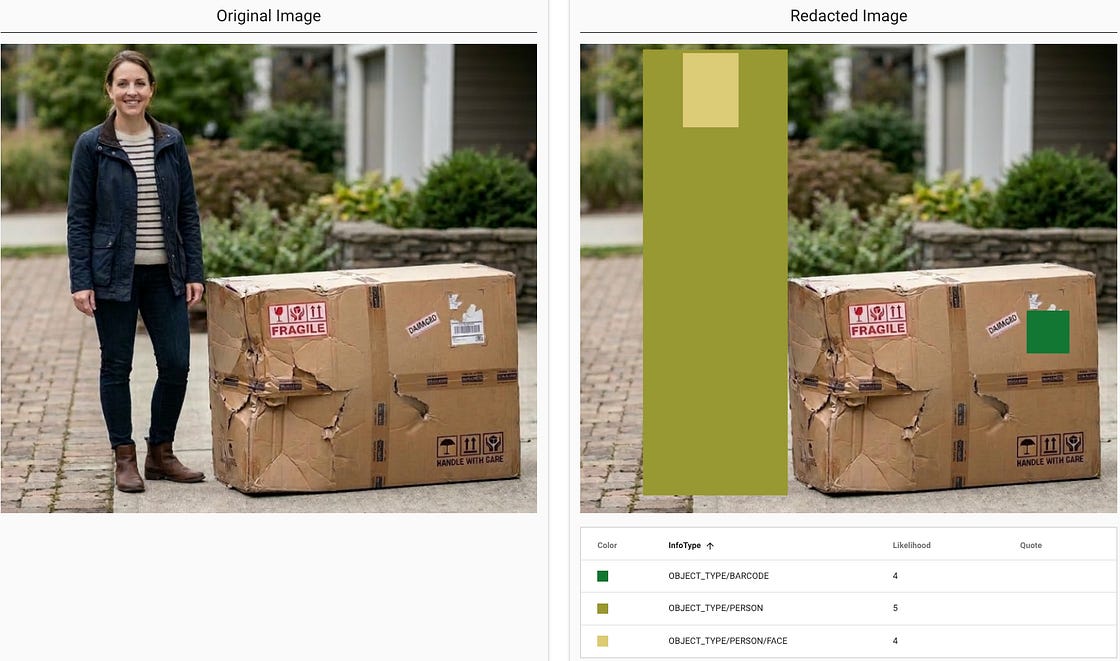
Google Cloud has updated Sensitive Data Protection (SDP) with AI-powered context classifiers and image object detectors to improve data security for AI workloads. These features allow for the identification and redaction of sensitive information, such as medical data, financial records, faces, and ID cards, within unstructured datasets used for model tuning in Vertex AI. SDP also functions as the core inspection engine for Model Armor and Security Command Center, providing managed discovery and automated sanitization across various data formats. For more details, check out the blog post.
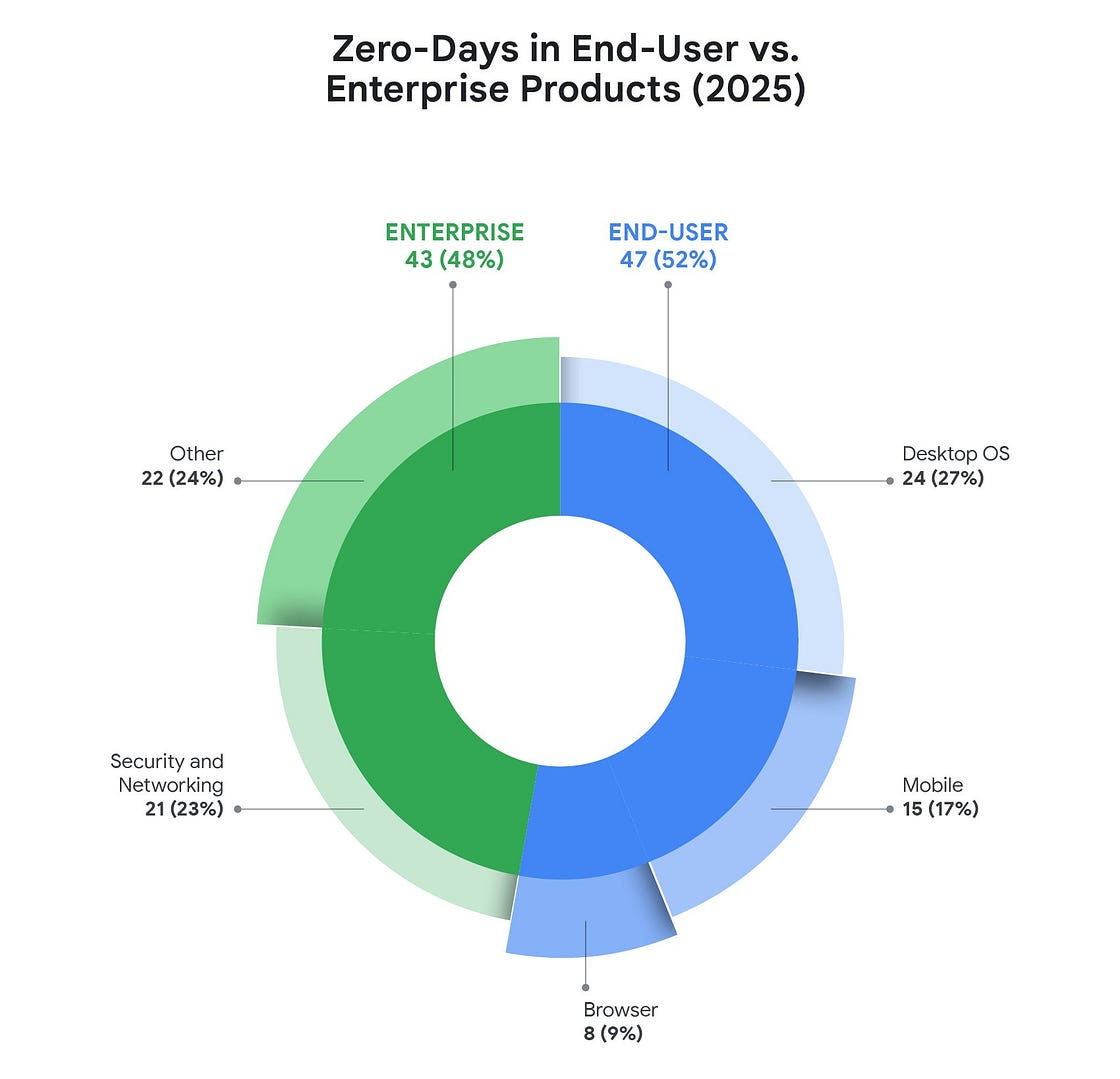
In 2025, the Google Threat Intelligence Group tracked 90 zero-day vulnerabilities exploited in the wild, noting a significant structural shift where 48% of these targeted enterprise technologies like networking equipment and edge devices. Looking ahead to 2026, the integration of AI is expected to accelerate both the discovery of vulnerabilities by attackers and the deployment of agentic security solutions by defenders. For more details, check out the blog post.
Developers & Practitioners
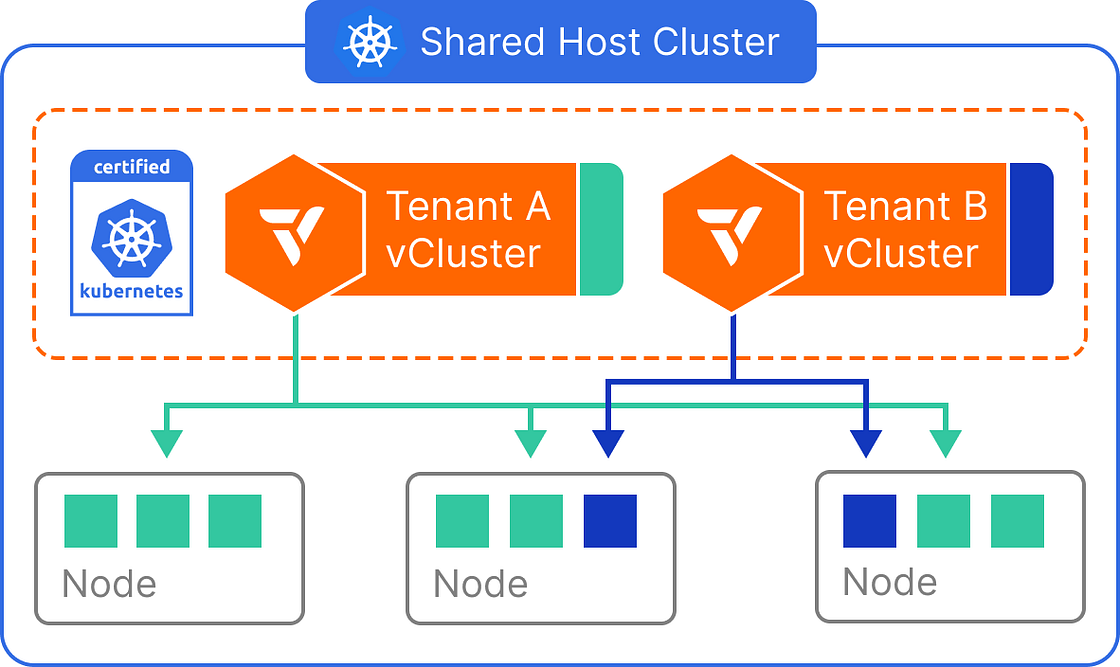
If you are looking to run AI models more affordably, there are two main efficiency problems: the high cost of giving a dedicated GPU to a single task and the complexity of managing separate setups for different teams. To address this, Google Cloud has published a guide, that uses a combination of three services:
GKE Autopilot: This automates the background infrastructure so developers don’t have to manually set up nodes or install GPU drivers.
GPU Time-Sharing: This allows multiple applications to “split” one physical NVIDIA L4 GPU, making sure the hardware isn’t sitting idle.
vCluster: It allows different teams to have their own private workspace and settings while actually sharing the same underlying hardware to save money.
The article provides a walkthrough of deploying Ollama using these methods. The result is a system where multiple teams can run their own AI tools in isolation on a single shared GPU node, reducing operational overhead and hardware waste.
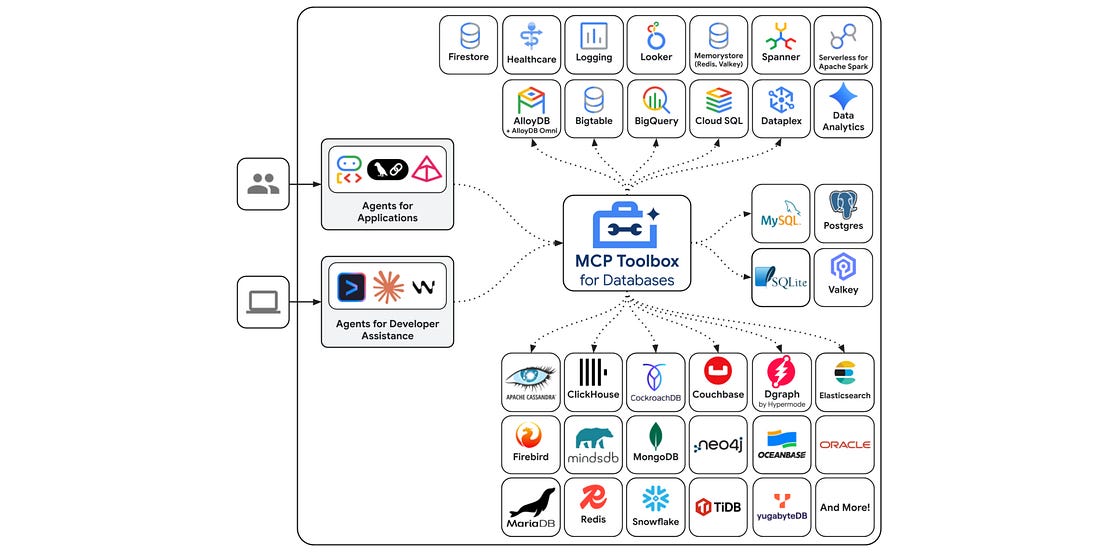
Google Cloud has released the Java SDK for the Model Context Protocol (MCP) Toolbox for Databases, providing a standard interface to connect AI agents with tens of different data sources including AlloyDB, Cloud SQL, and Spanner. This Java SDK allows developers using Spring Boot and LangChain4j to manage high-concurrency workloads and conversational state by mapping natural language intents to parameterized SQL statements through a tools.yaml configuration. Check out the announcement post and getting started guide.
Containers and Kubernetes
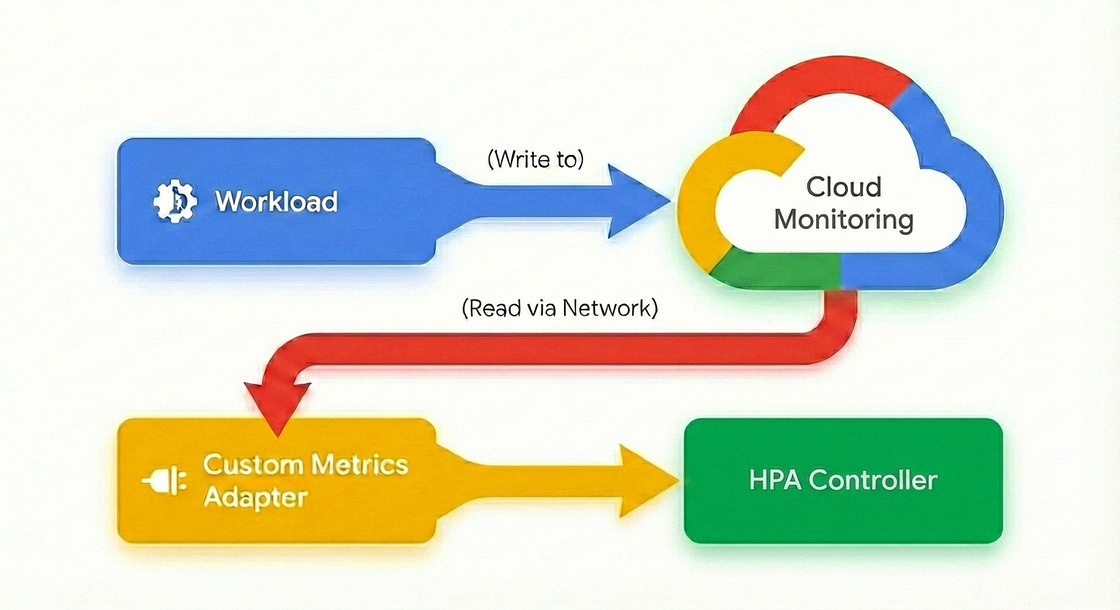
Google Kubernetes Engine (GKE) has introduced native support for custom metrics in the Horizontal Pod Autoscaler (HPA), removing the need for external adapters, intermediate agents, or complex IAM configurations. Previously, scaling on application-specific signals like queue depth or active requests required exporting metrics to a monitoring system and using a translator like the Stackdriver adapter. You can now use the HPA to source metrics directly from pods, which reduces scaling latency, eliminates the cost of ingesting metrics solely for autoscaling, and removes the operational risk of coupling scaling logic to the availability of an external observability stack. Check out the blog post.
Check out this article that positions Google Kubernetes Engine (GKE) as a high-performance foundation for telecommunications operators to modernize their core networks. It highlights two primary deployment strategies: cloud-centric evolution for full elasticity and scaling of mission-critical workloads, and strategic hybrid modernization for maintaining local control over latency-sensitive functions while using the cloud for the control plane and analytics. More importantly, by running workloads on a platform adjacent to Vertex AI and BigQuery, operators can transform network telemetry into actionable insights, especially AIOps.

Networking
Looking to design a reference architecture for building Generative AI applications using Retrieval-Augmented Generation (RAG) with strictly private connectivity on Google Cloud? This guide can be a handy reference for doing so. The design ensures that data traffic remains within a private IP space and does not traverse the public internet by using a multi-project structure consisting of a routing project, a Shared VPC host project, and dedicated service projects for data ingestion, serving, and frontend operations.
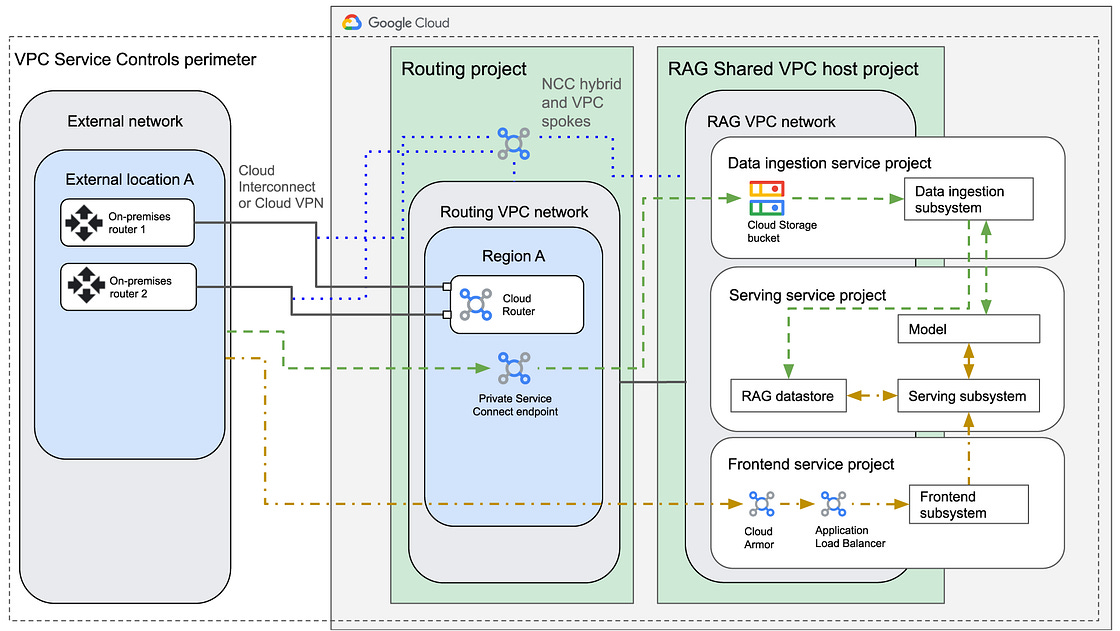
Infrastructure
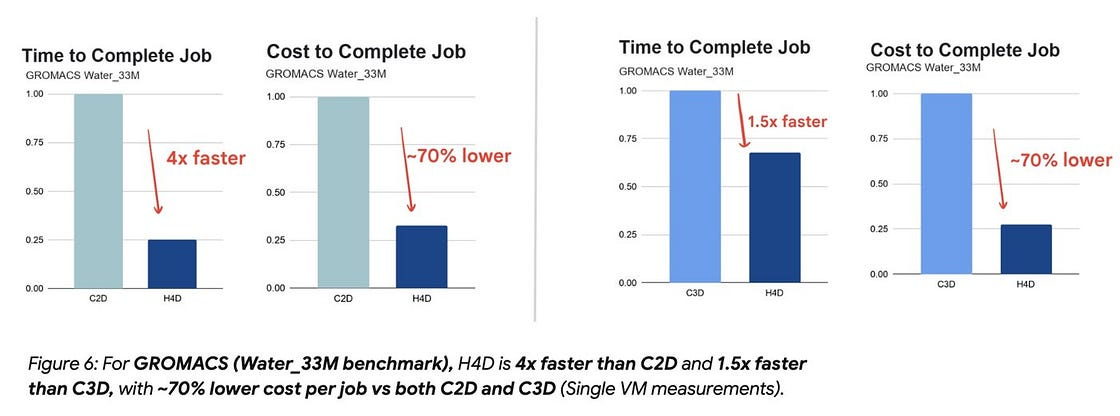
Google Cloud has announced the general availability of H4D virtual machines, which are designed for high-performance computing (HPC) workloads and powered by 5th Generation AMD EPYC processors. These VMs introduce Cloud Remote Direct Memory Access (RDMA) via the Titanium network adapter and use the Falcon hardware transport to reduce latency when scaling across multiple nodes. Benchmarks show performance improvements for molecular simulations, fluid dynamics, and electronic design automation compared to previous C2D instances. Check out the blog post for more details.
Customers
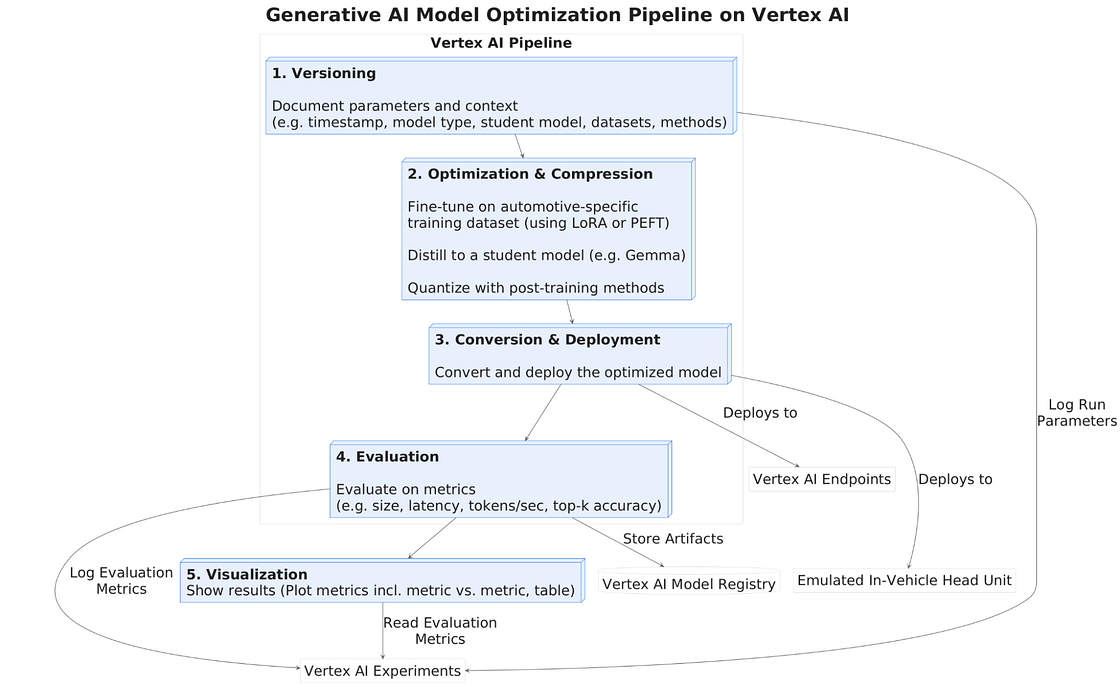
BMW Group and Google Cloud conducted a proof of concept to automate the workflow for fine-tuning, optimizing, and evaluating small language models (SLMs) for in-vehicle voice commands. The solution to move from LLMs to optimized SLMs was not straightforward as the blog post suggests and the workflow, which is a pipeline built on Vertex AI utilizes various compression techniques, followed by quality enhancement methods like Low-Rank Adaptation (LoRA) and Direct Policy Optimization (DPO) and more. Check out the blog post for more details and links to source code of the workflow.
Write for Google Cloud Medium publication
If you would like to share your Google Cloud expertise with your fellow practitioners, consider becoming an author for Google Cloud Medium publication. Reach out to me via comments and/or fill out this form and I’ll be happy to add you as a writer.
Stay in Touch
Have questions, comments, or other feedback on this newsletter? Please send Feedback.
If any of your peers are interested in receiving this newsletter, send them the Subscribe link.